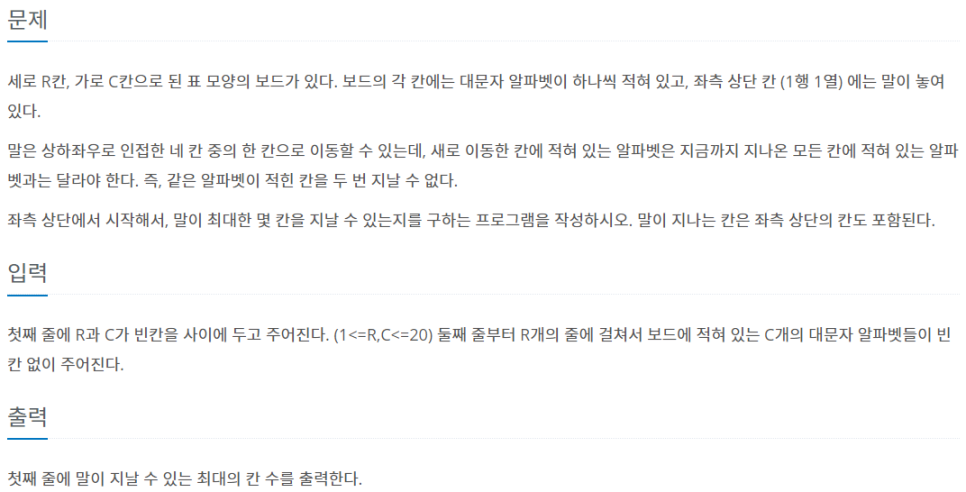
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Stack;
import java.util.StringTokenizer;
class Point{
int x,y;
public Point(int x, int y){
this.x=x;
this.y=y;
}
}
public class Main {
static String map[][];
static int index=-1;
static int dx[]={0,1,0,-1};
static int dy[]={-1,0,1,0};
static Stack<String> path;
static int MAX=-1;
static int r,c;
public static void main(String[] args) throws IOException{
BufferedReader reader=new BufferedReader(new InputStreamReader(System.in));
StringTokenizer token=new StringTokenizer(reader.readLine());
r=Integer.parseInt(token.nextToken());
c=Integer.parseInt(token.nextToken());
map=new String[r][c];
for(int i=0;i<r;i++){
String s=reader.readLine();
for(int j=0;j<c;j++){
map[i][j]=String.valueOf(s.charAt(j));
}
}
Point start=new Point(0,0);
path=new Stack<String>();
path.push(map[0][0]);
back(start);
System.out.println(MAX);
}
public static void back(Point point){
for(int i=0;i<4;i++){
int befor_x=point.x;
int befor_y=point.y;
if(befor_y+dy[i]<0 || befor_y+dy[i]>r-1 || befor_x+dx[i]<0 || befor_x+dx[i]>c-1){
continue;
}
String nextString=map[befor_y+dy[i]][befor_x+dx[i]];
if(path.contains(nextString)){
MAX=Math.max(MAX, path.size());
}else{
befor_y+=dy[i];
befor_x+=dx[i];
path.push(nextString);
back(new Point(befor_x,befor_y));
}
}
path.pop(); //back....
}
}
원래는 째로탈출푸는 것 처럼 visit_x..함수 쓰고 index--; 해서 back했는데 저렇게 하는게 좋은거같다..
stack을 사용해서 back할때 경로 삭제 해주고, 같은 알파벳이 경로내에있는지 체크하였다.
(메모리나 시간이 오래걸림..)
다른사람들 하는거 보니깐
if(visit[map[i][j]-'A'+1]==1) 이렇게 해서 해당 알파벳 존재 유무를 비교해준다.
이게 더 좋은 알고리즘 같다. 빠르고..메모리 절약..ㅠㅠ
다 어떻게 이런생각을 하는지....ㅠㅠ 뇌가 굳어서 나는 거의 알고리즘 직관적으로만 푸는듯 엉엉 예외란 예외는 다찾아야해.....
'코딩문제' 카테고리의 다른 글
| [백준알고리즘] 2048 (BFS) (0) | 2018.03.23 |
|---|---|
| [백준알고리즘] 숨바꼭질 (BFS) (0) | 2018.03.23 |
| [백준알고리즘] 유기농 배추 (DFS) (0) | 2018.03.23 |
| [백준알고리즘]2178 미로 탐색 (BFS) (0) | 2018.03.23 |
| [백준알고리즘] 팩토리얼 0의 개수 (0) | 2018.03.23 |